系统简介:
大数据的特点有体量巨大,而有价值信息的密度低,因此,需要采用大数据文本分类的技术,对海量数据进行分类整理。大数据文本分类技术能够按照用户预设的类别体系,将数据进行归类。实际的业务往往面临着不同的分类需求,例如新闻分类、简历分类、邮件分类、办公文档分类、区域分类等,这样就需要分类系统能够适应不同的分类标准。 灵玖大数据文本分类采用基于内容的分类和基于规则的分类两种方式,并支持两种方式的混合分类,能够进行多级分类,很好地满足实际业务要求。
主要功能:
数据样本训练分类:
为每个类别人工挑选样本,机器自动学习样本特征,对新的数据按照样本特征进行分类。
规则匹配分类:
为每个类别设置关键词表达式,机器按照精确设置的表达式进行分类;表达式支持“与、或、非、近邻”等复杂的逻辑符号嵌套。
数据样本规则混合分类:
将样本学习和规则匹配相结合进行分类,发挥二者的优势。
应用案例:
下图给出了样本训练分类方法的结果示例图:
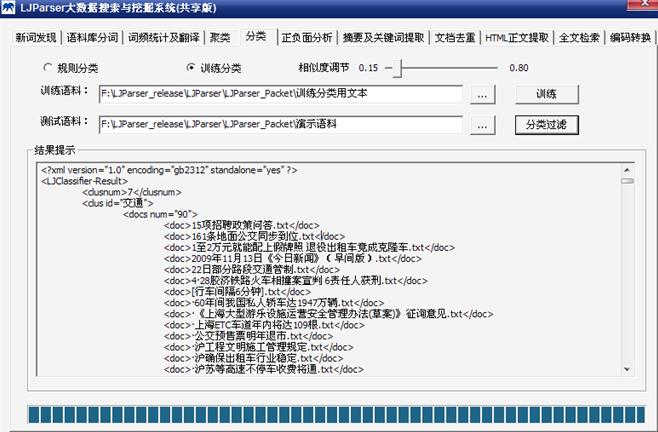
图1:样本训练分类结果示例
技术特点:
1、支持自动分类和规则的两种分类方式,而且支持两种方式的混合分类;
2、速度快,分类速度每秒100篇以上,平均准确率90%以上;
3、能够进行中英文分类和中英文的混合分类。
运行环境:
操作系统:Linux2.6及以上;Windows Server
硬件配置:1台服务器即可